读《The Ubiquitous B-Tree》
读完这篇论文,有种盲人摸象的感觉。好在确实对 B-tree/B+-tree 的基本原理有了些了解。 比如一些基础的概念,B-tree 的 order,B-tree 的插入/删除算法(里面涉及到平衡), B+-tree 相比 B-tree/LSM-tree 的优劣势。但它总归只是一个理论, 和实践还是感觉差距太远,没有“原来是这样”的感悟。后续可以尝试结合 InnoDB 的实现来阅读,但记住,一定要带着问题。现在就有点缺少引发思考的问题。
简介
先介绍背景:访问组织好的文件的方式通常有两种 Sequential and Random。 然后说,对于随即访问,有 index 访问起来会更快,这里用文件夹和文件夹上的 A-Z 来描述索引,生动形象。(其实比作字典索引,也挺形象的。)
这篇论文的核心内容:比较了 B-tree 的一些变种,尤其是 B+-tree, 展示了为什么它变得如此流行。论文还调查了 B-trees 相关的一些论文。 另外,它还讨论了一种基于 B-tree 的通用文件访问方法。
注:当我基本看完这篇 paper 的时候,我发现它对 B+-tree 的描述并没有很多
B-Tree 基础
B-tree 的基本性质,order 是变量。插入删除时都要保证这个性质。
In general, each node in a B-tree of orderd contains at most 2d keys and 2d + 1 pointers, as shown in Figure 4. Actually, the number of keys may vary from node to node, but each must have at least d keys and d + 1 pointers. As a result, each node is at least 1/~ full
B-tree 的优雅之处在于插入和删除都能保持树的平衡。 任何一个查找操作最多访问 1+logdN 个节点,N 是节点总数,d 是 order。 如何保持平衡(balancing)是这里着重介绍一个点。
插入遇到节点 full 的话,需要 split。最坏的情况,是一直递归到 root,
root 进行 split,这样树的高度会加一。删除的时候,如果是删除一个非叶子节点,
则需要补一个相邻的节点进来。通常是找比它大的那个相邻节点。如果遇到
underflow 的话,也要重新平衡,就从邻居叶子借一个过来。
也可以多借几个来让两个邻居更均衡。如果加起来还不够 2d,则可以 concatenation。
查询,插入,删除的最坏复杂度都基本是logdN。插入和删除的细节看 wikipedia 更好懂一点,2333。一个不足是它的 next 性能不够好,logdN。 并且一个查询要把沿路的节点都记录下来,并且要缓存 h(高度)个节点。
Unfortunately, a B-tree may not do well in a sequential processing environment. While a simple preorder tree walk [KNUT68] extracts all the keys in order, it requires space for at least h = logd(n + 1) nodes in main memory since it stacks the nodes along a path from the root to avoid reading them twice. Additionally, process- ing a next operation may require tracing a path through several nodes before reaching the desired key. For example, the smallest key is located in the leftmost leaf; finding it requires accessing all nodes along a path from the root to that leaf as shown in Figure 12.
B-tree 变种
插入和删除的时候,split 和 contatenation 都可以延迟,通过和邻居平衡。
-
B*-trees 是一种节点必须有 2/3 满的树。单节点满的时候,从旁边的节点挪一挪。 两个节点满的时候,正好分为 3 个 2/3 的树。说这种方法,空间使用率最少有 66%。
-
B+-trees,只有叶子节点有 key,上层只有 index。index 的值不一定是存在的, 部分 delete 操作可以不需要处理 index。index 与 key 分离。
- Prefix B+-trees,给 index 省点空间。对一和二没太明白。
Thus, virtual B-trees have the following advantages: 1) The special hardware performs transfers at high speed, 2) The memory protection mechanism isolates other users, and 3) Frequently accessed parts of the tree will remain in memory.
-
Compression,key 的前缀压缩和指针压缩。指针压缩可以是基础地址+偏移。
-
Variable Length Entries,没看懂论文说了个啥。
-
Binary B-trees,order=1 的 B-tree,适用 one-level store,不懂这是啥。
- 2-3 Trees and Theoretical Results,也是适用 one-level store。
说空间利用率还不错,可以有 69% 左右。然后说消除自下而上的更新对性能影响很大。
The small node size makes 2-3 trees impractical for external storage, but quite appropriate for an internal data structure.
InnoDB 的 B+-tree 结构
Jeremy Cole 的几篇博客介绍的还挺好的,图文并茂。 B+-tree 的 Node 在 InnoDB 里面对应的概念是 Page,一个 Page 默认 16KB。
叶子节点的 page 的大致结构长这样,非叶子结点有点不一样。主要区别就是非叶子节点的 page, 它的数据里面存的不是 key/value,而是一个类似指针的接口,里面存了 min key 和 page no。 page no 是叶子节点 page 的索引。 B+-tree simplified leaf page non-leaf page
{kind=link}
在一个 level 里面,page 与 page 是双向链表 level
{kind=link}
Page 的详细结构(按照我目前的理解:一个 page 并不是对应一个文件) detailed-page
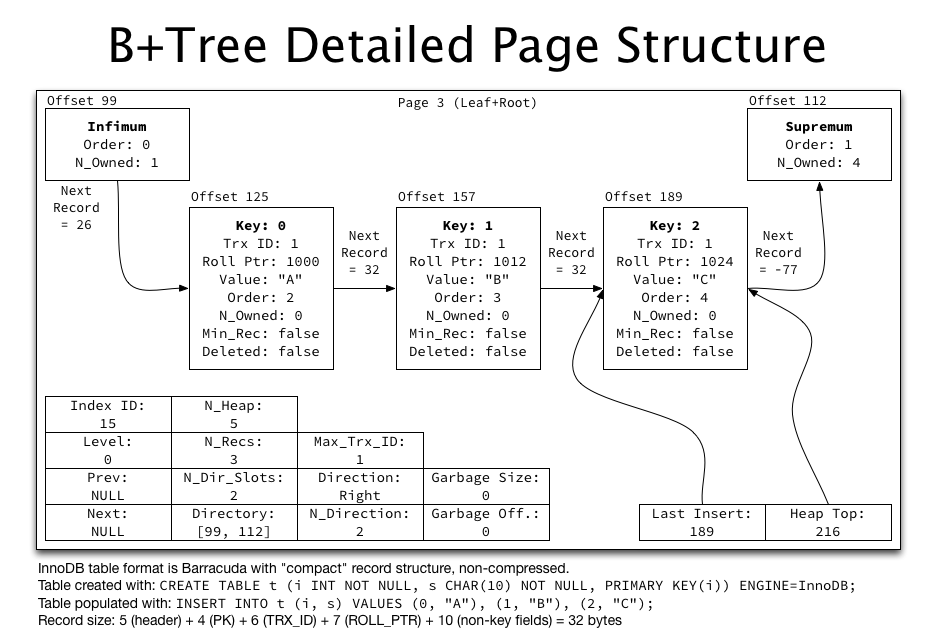{kind=link}
这里只记录了基本的 B+-tree 结构,没有纪录 InnoDB 是怎样处理读取,写入,删除的。
Comments